

A daily blog of my robotics journey in SF, Summer 2025
What is this?
Since the 4th of May, I’ve been working full-time on robotics. I use this space to collect my daily thoughts, document what I’ve worked on, and note down any questions that come up. Sharing this helps me stay accountable and reflect on whether my day-to-day efforts are effective in pursuing my goal of building a robotics company.
Only data collection
Thursday, 2nd of July
Today I collected 349 episodes of data. It was very monotonous and boring, but the ability to endure boring work is important for success.
Some thoughts from the day:
I see how a limitation of imitation learning is that it’s hard for the robot to become better than the demonstrations. For better results, robots presumably need some ability to experiment on their own. Reward models might also be an interesting avenue: in this approach, a model (separate from the control policy) evaluates the video and assigns a score from 0–100 for each frame based on how close the robot is to successfully completing the task. This would let the robot collect data autonomously, and you could iteratively retrain the model using only the best samples.
For my chess game, it would be better if the robot’s camera were at the bottom rather than the top of the gripper. This way, the arm maintains visual contact with the piece throughout the entire motion.
More cameras (>2) likely help when training precise models.
Recording an episode takes 15 seconds plus 30–40 seconds to encode/compress the videos. If I collect more data, it’s worth exploring whether I can batch-encode all videos after recording.
First policy results!
Tuesday, 1st of July
Instead of just collecting a thousand episodes and hoping for the best, I want to think more intentionally about how to maximise learning while doing it—and ideally create shareable insights for X. If I later write a blog post, it would be great to include useful learnings along the way.
One thing my thesis supervisor at OpenAI taught me is to always sketch the plots you want to show before writing any code. Following that advice, I drafted some plot ideas and outlined the data I’d need to collect to generate them.
Research questions I want to run experiments for:
Which policy performs best: ACT, Pi0-fast, or SmolVLA, across different dataset sizes?
100 episodes | 500 episodes | 1000 episodes | |
ACT | |||
Pi0-fast | |||
SmolVLA (finetune) |
2. How does policy performance improve with training steps?
20k | 40k | 60k | 80k | 100k | |
ACT | |||||
Pi0-fast | |||||
SmolVLA (finetune) |
3. How do data quantity and task diversity affect accuracy? (All experiments use the best model from experiment 1)
20k | 40k | 60k | 80k | 100k | |
ACT | |||||
Pi0-fast | |||||
SmolVLA (finetune) |
Writing this down made me realise that these experiments might take considerable effort, and I questioned whether this is the best use of time—or whether I should instead focus on the main goal: getting the robot to play a full game autonomously.
Pros of doing the experiments:
They’ll help me build intuition for how well different models perform and how dataset size and diversity affect learning.
They could result in a compelling blog post that’s valuable for others starting out in robotics.
Cons:
It’s a detour that could slow progress on the main objective, which risks losing momentum—something I’ve found crucial for maintaining motivation and output.
I decided to structure data collection so I can still run these experiments later, but first focus on getting the robot to play a full game.
After yesterday’s training failed due to insufficient Lightning AI credits, I topped up and resumed training the ACT model to 100k steps. While it was running, I evaluated the 20k checkpoint. Out of 30 attempts, it succeeded in 7 — roughly a 23% success rate.
That’s not great, but it does confirm that the model understands the visual hints (the overlaid circles) from the context camera - that was the main goal of this test.
The most common failure mode was the gripper missing the piece during pickup. I suspect the model overfitted to the exact chessboard position in training and couldn’t handle small shifts. The second most common issue was the gripper either releasing too early or not at all - something I expect will improve with more data.
I spent the rest of the evening collecting data by replaying the Kasparov vs. Van Foreest (2021) game. I controlled the black pieces and used the same colour overlays as in the earlier experiment.
I noticed two interesting things:
Captures require two policy runs: first to remove the opponent’s piece, then to move our piece into place. I’ll need a good strategy to choose the drop-off location for the captured piece—ideally somewhere close to the robot and not too close to other pieces.
Castling also requires two moves: my current visualiser only draws one arrow, so I’ll need to update the logic to handle two.
Also, my piece-detection model struggles most with queens and kings—likely because they appear less frequently and there’s less training data for them. I wonder if the same issue will arise in the action model, since some pieces are moved less often. Playing more endgames could help balance this out.
Getting to 80% accuracy might not be too hard, but hitting >95%—let alone 99%—will be difficult. In the Kasparov game, there were 42 moves total, plus 12 captures. So 54 actions are needed. At 99% accuracy per action, the probability of a flawless game is only 58% (0.99^54).
Damn. That’s going to be hard. But also exactly why I’m doing this: to reach the hard parts of robotics and develop a concrete understanding of what it really means to build capable robots.
Tomorrow’s focus: more data collection.
Writing these words just before midnight, I can’t help but smile—each week I spend working on robotics strengthens my conviction that this field will be revolutionary within my lifetime, and is something I want to go all in on over the next few years.
Modifying data recording script, collecting 100 episodes, first training run with ACT
Monday, 29th of June
Today was a really good day. I implemented a new version of the data-collection script for the SO-100, where the user can click on an image from the context camera’s view to add a red circle indicating the piece to be moved, and a blue circle indicating the target square.
To test this method, I used a simple example: two rooks set up on the chessboard, each meant to be moved two squares forward. The challenge is that the model needs to infer which of the two should be moved. I collected 100 episodes—50 for each piece—which took half the day.
Below is a screenshot of the coloured overlay. You can view the full dataset here.

I then reviewed the episodes for quality, deleted the ‘bad’ ones using Ville’s Pikodata, and merged the datasets with Phospho. After that, I started training an ACT model. This last step took longer than expected because:
a) uploading the merged dataset was slow,
b) I had trouble starting the training run — it requires an unexpectedly large amount of RAM (~60 GB!) despite a batch size of 8 and each episode lasting only 15 seconds, and
c) I ran into issues with Wandb tracking. There was no clear error message—just a timeout during initialisation. The root cause was a run name that conflicted with a previously deleted run, which didn’t fail cleanly but instead triggered a silent timeout.
Working through the LeRobot code
Friday, 28th of June
I spent the morning reading the first five blog posts of Benjie Holson’s General Robots Substack. He was laid off from Google Robotics during the recent restructurings and now shares his thoughts on building robots. I enjoyed it a lot and strongly recommend it.
I also read this blog post by Dyna Robotics. Unlike Physical Intelligence, which works on general-purpose robotic arms as a pure research company, Dyna focuses on making single use cases work. This approach makes much more sense to me — it’s clear that we’ll need significantly more data than we currently have for general-purpose robotics, and it’s still unclear which data modalities will get us there. World models, simulation, or egocentric video don’t yet seem good enough to close that gap anytime soon.
By prioritising working use cases over pure research, Dyna can generate revenue early while positioning itself to scale once better data modalities and model architectures emerge.
What’s remarkable about Dyna’s robot is its long-duration performance: it ran for 24 hours straight, folding 850+ napkins at ~60% of human speed with a 99.4% success rate, requiring zero interventions. This is exceptional. The blog post explains, at a high level, how they achieved this: they train a model to estimate how well the robot is progressing toward completing a task. As I understand it, they then take the successful episodes and use them as training data for further iterations, allowing the model to learn from its own experience. This builds on research by Jason Ma (CTO of Dyna) at DeepMind, detailed in this paper.
In the afternoon, I revisited the LeRobot code. My plan is to train an ACT-based method to move objects (highlighted with a red circle) to a target location (highlighted with a blue circle). To do this, I need to record data with camera input augmented by these visual cues.
The code for dataset recording and policy execution is in the record.py file of LeRobot, which contains a robot.get_observation() method. My plan is to:
Create a copy of record.py.
Build an interface that lets the user click on the image to place the red and blue circles before recording starts.
Integrate this into the high-level control loop of my chess application so that the visual cues are generated automatically during data collection.
Research on robotic arms & Hugging Face hackathon winner demos
Thursday, 27th of June
I spent the day researching robotic arms, mainly from Trossen and Arx. What stood out was how prominently Trossen advertises its integration with LeRobot on their website. It made me wonder whether LeRobot might become the standard interface layer in robotics over the next few years.
I also came across this video by Trossen showcasing their LeRobot integration. I found it especially helpful because I’ve been curious about how big the leap is from working with the SO-100 to using a Trossen arm. The video gave me the impression that much of what I’m learning with the SO-100 will transfer directly.
Most of the afternoon went into reading through the LeRobot codebase.
Later, I watched the demo videos of the top 30 winning teams from the LeRobot hackathon. As someone new to robotics, it was inspiring to see the range of ideas, how much can be built in a weekend, and the general research directions people are exploring. Highly recommend checking them out.
In the evening, I had dinner with Jannik Grothusen, solo founder of the Robot Learning Company. It was interesting to hear his perspective after several years in the field. While he strongly believes in robot learning, he also thinks the current hardware is overpriced and suboptimal for robot learning — which is why he plans to build a bimanual robot-learning dev kit cheaper than what you can buy from Trossen or Arx.
Webcam Integration and the Long Tail of Labelling
Wednesday, 26th of June
Today was a really productive day. I added a camera module that reads from a connected webcam and integrated it with a new script that streams the chessboard and displays the detected board in real time. While running the script, I noticed that the main bottleneck in the chess-robot pipeline is still board segmentation and piece detection.
To make data collection easier, I added a script that streams the webcam feed to a desktop window and allows the user to save every n-th frame. This makes it possible to move pieces around and automatically capture images, instead of manually taking photos with a phone. It’s also the first time I’ve added webcam-based data that will actually be used in the final application.
I labelled around 50 additional images for both segmentation and piece detection, and retrained the models. However, I’m still not satisfied with the results — it looks like I’ll need significantly more labelled data.
I also spent some time exploring the LeRobot codebase, read through the example scripts, and calibrated my arms. I found the simulation script particularly interesting, as I haven’t worked with robotic simulations before, even though I know it’s a major part of the field.
Over the next few days, I want to focus more on the robot code — reading more of the LeRobot internals during the day — and continuing to label data for the pieces in the evenings.
Adding chess board orientation, next move prediction and varying computer strength
Tuesday, 25th of June
One major missing piece was enabling the computer to determine the correct orientation of the chessboard. Without this, the PFN — and therefore the next-move prediction — would be incorrect. I considered ways to detect the orientation automatically, but since it’s impossible to infer reliably at all stages of the game, especially in the endgame, I decided the user will need to set it manually.
I also integrated Stockfish to predict the next move and made the engine strength configurable, so you can practise against the robot at different difficulty levels. Ideally, it could also provide verbal feedback on your moves — but I’ll leave that as an optional feature for later.
Finally, I tidied up the readme of the repo.

Reshuffling chess analysis code
Monday, 24th of June
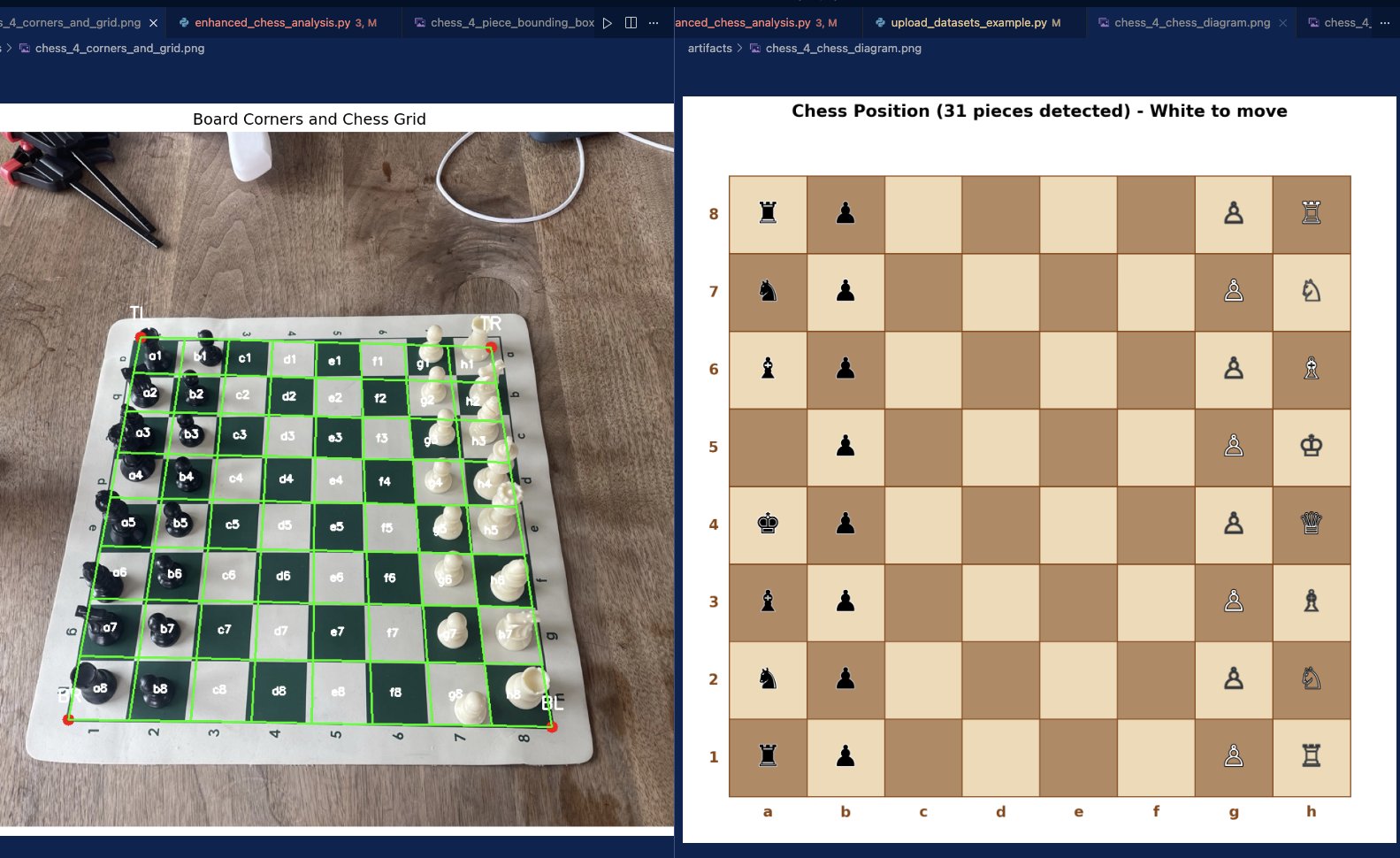
The chessboard analyser (the computer vision part) is working well overall, but I ran into a few issues — most notably, pieces were sometimes being assigned to the wrong squares, despite being correctly detected with bounding boxes.
Last week, I relied heavily on Cursor’s agent mode, which eroded my intuition for the overall code structure. As a result, it became hard to reason about what was missing or going wrong. To address this, I spent today introducing a clean dataclass structure that represents the full state of the chessboard, including intermediate results. Implementing this required changes across the codebase, which helped rebuild my understanding and led to partial rewrites.
I’m still unsure how much of a speed-up agent mode actually provided. My current takeaway is to only use it for making targeted changes, and to avoid delegating structural decisions to it.
Previously, piece-to-square assignment was based on whether the centre of a bounding box fell within a square. However, this approach proved unreliable, especially for taller pieces like the queen and king, because the camera isn’t positioned directly overhead. In those cases, the centre point often landed in the wrong square. I’ve now changed the method to use a point located at one-quarter of the bounding-box height, which seems to give more accurate results.
Here’s the current status quo:
YC AI Start-up School week
Monday 16th of June to Sunday 22nd of June.
I attended Y Combinator’s Startup School. The two-day conference had an impressive line-up of speakers, but most of the talks didn’t offer much beyond what the speakers had already shared in previous appearances.
What stood out most to me was Chelsea Finn’s recap of Physical Intelligence’s work. While it was essentially a condensed walkthrough of what’s already available on [their blog](https://www.physicalintelligence.company/blog), it was still valuable to hear her personal framing and emphasis. It was also interesting to pick up on some of her views - like her current lack of enthusiasm for data sources beyond teleoperation.

Another good talk was Andrej Karpathy’s meta-talk on LLMs and interacting with them. Karpathy introduces a variety of analogies and mental models for how to think about LLMs and for designing software around them.
The highlight of the conference, though, was meeting other attendees — especially fellow Europeans. Being there acted as a strong filter for both technical depth and startup interest, a combination that’s sometimes hard to find at ETH. I spent the rest of the week reconnecting with people one-on-one, hosting an ETH alumni event, meeting a friend at Founders Fund, and organising a dinner for Germans in the Bay Area.
Midweek, I found myself frustrated about not getting much actual work done. But after jotting down a few thoughts in my notebook, I realised that this — meeting thoughtful, like-minded people — was exactly what I’d been missing in the months before. Many of these early conversations felt like planting seeds for long-term relationships.
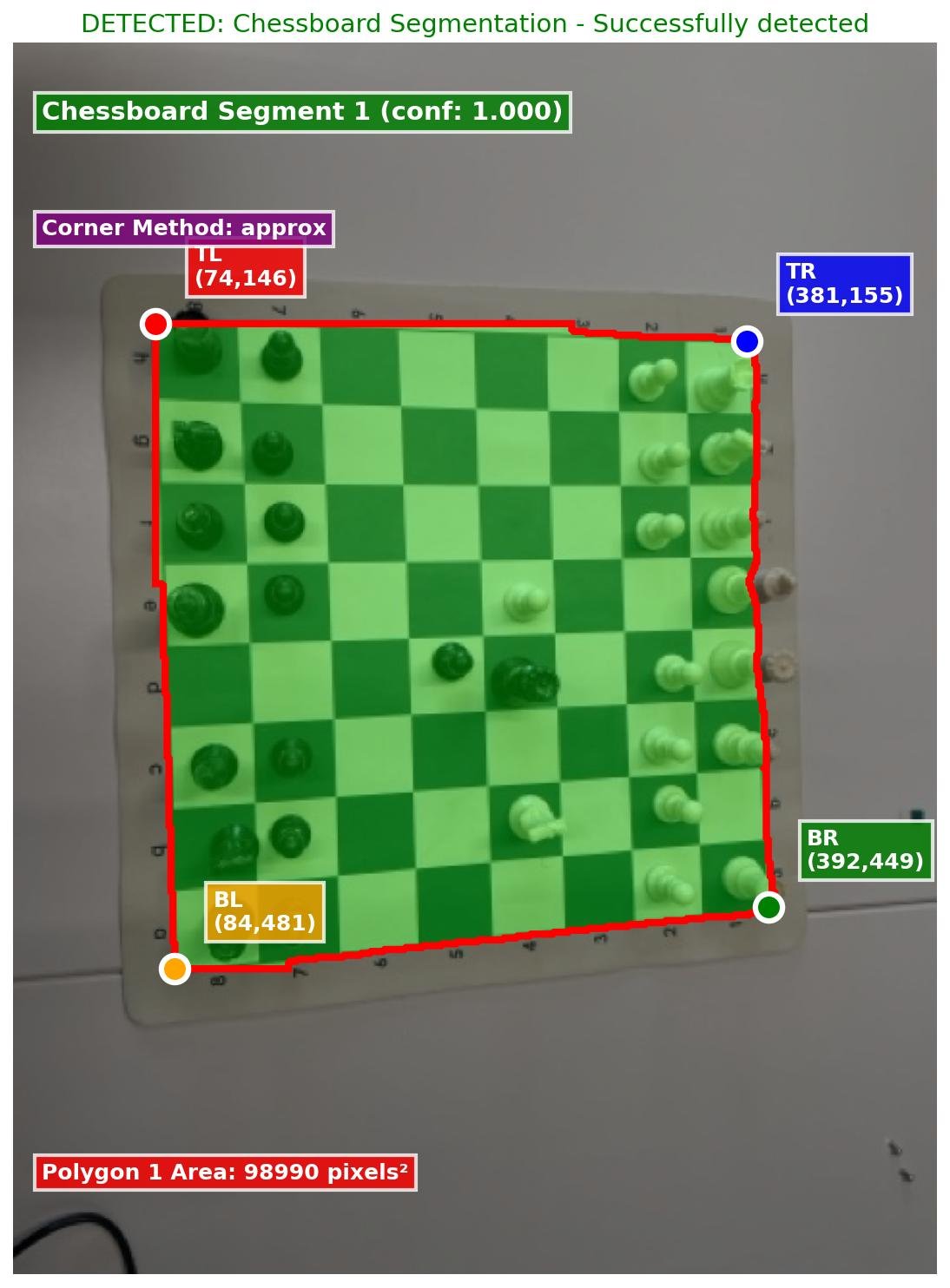
Segmentation model working
Friday, 13th of June
Spent more time setting up segmentation-model training and inference, tidying up code, and adding a class and CLI script to run inference on images easily. I’ll also use this class later in the main control loop for the chess robot to repeatedly run inference and store the full application state.
Here is a look at what the model is able to infer:
Working on LeRobot code because of GCP outage
Thursday, 12th of June
I worked on copying the segmentation model I trained on Roboflow yesterday. GCP had an outage that affected Roboflow, so I couldn’t download my data.
Instead, I spent time working through the LeRobot code and started taking notes in Notion to retain more knowledge and avoid repeatedly jumping back and forth through the code.
I reorganised my notes in Notion and realised I should keep my daily-notes blog up to date. It might be very useful in a few weeks to review my thoughts and decision processes. It’s also a treasure trove of links and resources — and potentially a huge context I can feed into an LLM to discuss ideas.
I read Rerun’s blog post on their $17m Series A. They’re ~50 team members, based in Stockholm and, as I understand it, pre-revenue. What I found interesting is that they picked the most “boring” but critical part of building robotics — data management — and are building a solution around it. It’s like the classic startup advice to build for a boring industry, but applied to the boring part of a hyped technology.
Moving from Edge Detection to Segmentation
Monday–Wednesday, 9th–11th of June
I encountered issues with board detection using a traditional computer-vision approach (no ML). The edge detection didn’t generalise well across images and especially struggled with
(a) varying distances between the camera and the chessboard, and
(b) pieces blocking the board edges.
Below is an example where it works well, and a second example where a slight change in camera angle and piece placement completely breaks it. Even small deviations in corner detection lead to a misaligned grid and therefore a very poor mapping of pieces to squares.


So instead, I tried detecting the contours of the board using a YOLO model that detects polygons (not bounding boxes). That didn’t work very well. Next, I explored detecting bounding boxes of the chessboard and then applying the Hough Lines method (traditional CV), but that approach became messy. At this point, I started wondering whether segmentation might work better with my small dataset.
I spent a night labelling data for both bounding-box detection and segmentation, and trained Roboflow models for both. I trust that they’re running all possible optimisations in the background, so paying them $60 for this felt like a good use of money to save time.
The results showed that segmentation actually worked quite well, so I wrote code to train a model locally to
(a) make my code fully open and usable by others, and
(b) enable easy retraining in the future without paying for a Roboflow subscription.
One thing I noticed during Roboflow’s training process was that they used checkpoints pretrained on large datasets. I incorporated this into my own training code as well.
Going to bed, I questioned whether spending the entire last week on the diffusion course was the best use of time. It’s hard to say. On the one hand, doing this seems to go against the usual advice of staying super focused as an entrepreneur. On the other hand, it’s also important to understand things deeply — especially if robotic ML models will be at the heart of the company — and my opportunity cost of doing this now may never be as low again.
Finished the Diffusion course
The week of 02.06. to 07.06.
I spent the week working through the course. It took longer than expected, but it was very helpful in developing intuition for flow matching and diffusion models.
I also found interesting statistics on robots in Europe:
https://www.bruegel.org/blog-post/growing-presence-robots-eu-industries
Meta released its V-JEPA 2 model and paper. V-JEPA is a world model (physics-grounded video generation) and therefore relevant to robotics.
Diffusion course lecture 2
Saturday, 31st of May
Worked through lecture 2 of the diffusion course. Putting lecture notes into ChatGPT is a game-changer for the speed of learning. I wish I’d had this during my master’s.
Problem set 1 for the diffusion course
Friday, 30th of May
I started working on the first problem set of the Introduction to Flow Matching and Diffusion Models course. I initially expected the course to take about three days, but it’s looking more like five–six. Still, I think it’s a worthwhile investment — a solid understanding of diffusion models is important for where things are heading.
I had lunch at the European Founders Embassy, then visited Founders Inc at Fort Mason, where I met two robotics founders, Ali Agha and Pierre-Louis Soulie. It’s an interesting space — an old military barracks — with a high density of robotics teams.
I also ran into the team behind this robotics demo: a mini factory in a glass box that automates electronics assembly. They had been demoing it the day before, and it was great to connect in person.
Detour start: 6-lecture course on Diffusion and Flow Models
Thursday, 29th of May
The next subsection in the AI for Robotics book covered diffusion models. While I understand the basic idea, I still don’t grasp them at the fundamental level I’d like. This has bothered me consistently for the past two years. Diffusion models show up everywhere now: images, video, proteins — and increasingly in leading robotics models.
Two months ago, I bookmarked the course Introduction to Flow Matching and Diffusion Models by Peter Holderrieth. Now, during my first week in San Francisco, I’m in a good headspace and not feeling rushed. It felt like the right time to work through it.
This is admittedly a detour from a detour — reading the AI for Robotics book instead of making faster progress on the chess robot — but I’m confident that deep understanding will pay off over the next few years.
I also came across this demo on X, showing a robot automating repetitive manual tasks, starting with electronics assembly. An even more compelling approach might be to begin with teleoperation, especially by workers in threshold countries. This removes the need for model training at the start and uses wage arbitrage. Over time, these teleoperated sessions generate large-scale interaction data, which can train task-specific models. As those improve, less teleoperation is needed due to emerging generalisation. Eventually, this data could support training a foundation model capable of zero-shot generalisation across a wide range of manual tasks.
More progress on
AI for Robotics
Wednesday, 28th of May
I continued reading the AI for Robotics book, covering pages 120–220. The chapter after point clouds focused on robotic foundation models. I found the following especially interesting:
I already knew the Kaplan et al. scaling-laws paper, but this section introduced me to the Chinchilla paper and its replication studies, which refine our understanding of compute-efficient scaling. They show how to optimally allocate data and model size for a given compute budget.
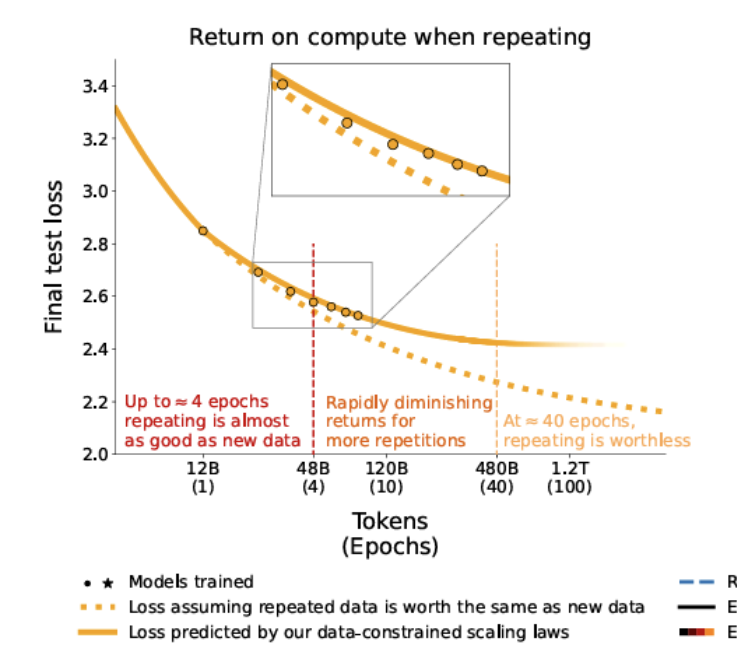
The paper Scaling Data-Constrained Language Models had a few striking findings:
Training on 4 epochs of a static dataset performs about as well as training on newly collected data.
Training beyond 40 epochs yields negligible gains.
Sorscher et al. showed that typical scaling laws (training loss vs. dataset size) can be broken through curriculum-style pruning:
In data-rich settings, pruning easy examples improves performance.
In data-constrained settings, pruning hard examples is more beneficial.
This challenges the idea that “more data is always better” and emphasises the importance of data difficulty and curation strategy.
These two robotics papers sounded interesting:
SayCan: A two-stage framework. The overall execution is brittle — failure in any single skill causes the whole task to fail.
An LLM estimates whether a proposed decomposition into low-level skills is likely to succeed.
It also predicts the success of each skill primitive given the robot’s state and environment.
Inner Monologue: Builds on SayCan by adding feedback and retries. The LLM reflects on whether a subtask succeeded and can reattempt it, making the system more robust.
I noted these papers down to explore later
Open X-Embodiment: Robotic learning datasets and RT-X models
Physically Grounded Vision–Language Models for Robotic Manipulation
Random idea:
I’m curious whether you could bootstrap robotic learning by starting with a single pre-trained skill (e.g. “pick up a ball and place it in a basket”), then use an LLM to generate small task variations (e.g. place it on a shelf instead) and evaluate whether the outcome succeeded. This could provide self-supervised signals and steadily expand the robot’s skill set without manual labelling.
A bit sick and learning about point clouds
Tuesday, 27th of May
I tried continuing the AI for Robotics book but couldn’t concentrate due to a headache and light fever. The next chapter covered LiDAR and point-cloud methods, so I watched this talk instead. It was useful to learn about typical problems in point-cloud processing: segmentation, object classification, surface detection, and generating 3D avatars from prompts.
I talked to an investor who helps connect cofounders, and I met Julian (founder of codarobotics.ai) via X. He’s trying to build a world model and sell it to robotics companies for evaluation.
Flying to San Francisco & Started Reading
AI for Robotics
Monday, 26th of May
I’m moving to San Francisco for two months to continue working and learning about robotics together with five friends in a hacker house.
I read the first 120 pages of AI for Robotics on the plane. The book isn’t a full guide to robotic foundation models but offers a medium-depth overview of subfields feeding into robotics and the most important research in each.
Better chess piece detection & code cleaning
Thursday, 22nd of May
I had 50 more images labelled, and the new model works much better. Not perfect, but now good enough that I can use it to annotate new data even faster.
I cleaned up the code for downloading and cleaning data to make it reproducible and easier to wrangle if I lose files.
Board detection
Wednesday, 21st of May
My labeller finished annotating the first 60 images. It’s not 100% perfect, but it’s promising and good enough to wrap a first version of the model into a workflow. Ishrat, my labeller, will continue helping annotate more data. I paid €50 for 60 annotated images — definitely worth the time saved.
Someone on X suggested using SAM to label data automatically. I’m curious whether that might work, but for now manual labelling works well and I don’t want to lose momentum experimenting.
I also found more chess-piece datasets on Roboflow. If I want the model to generalise across different board types, merging these datasets into a unified dataset could be useful.

Detecting the chessboard: I started working on detecting the individual tiles so I can build a FEN/PGN representation of the game. [This blog post](https://medium.com/@siromermer/extracting-chess-square-coordinates-dynamically-with-opencv-image-processing-methods-76b933f0f64e) was very interesting. After rewriting parts of the code, I’m starting to get some good results!

Chess piece detection
Tuesday, 20th of May
I’m flying to SF on Monday. I’m not sure whether collecting data here makes sense if I can’t use it in SF initially. So the obvious things to work on this week are:
reading out the chessboard, and
feeding it into a chess engine to get the next move.
I’m going to train a simple YOLO model to detect the pieces. I looked into existing datasets and found this one on Kaggle. I trained a YOLO model on it, but it doesn’t transfer well to my data.
I need to train on more of my own images — maybe by playing 1–2 games and capturing every second position from different angles. I’ll use a freelancer I’ve worked with before on Upwork to do the labelling.
I explored labelling platforms and decided to go with Roboflow (which is more of a model-training company) to annotate the data, since their interface is fast and downloading labelled images is easy.
Below is a picture of the predictions of a model trained on a different dataset, applied to one of my images:

I met Simon in person at the office today — we originally connected a few weeks ago through my posts on X. He’s visiting Berlin and wanted to see the SO-100 robot I built. His family runs a precision steel-casting business, exactly the kind of European manufacturing SME that could be a future customer.
Talking to him was incredibly valuable: we discussed how companies like his approach their processes, how much robotics they already use, where they struggle, and what they’re looking for.
Simon is a founder himself and is considering building his next company in robotics. He’s one of those rare people who deeply understands both manufacturing and startups, which made the conversation especially insightful.
He was also very kind and invited me to visit their factory once I’m back from SF — and even offered to introduce me to other companies in the region. I have no connections to SMEs, so I’m especially happy to have met Simon!
Back in Berlin & work on Substack
Monday, 19th of May
I spent most of the day working on my Substack post about what I’m aiming to achieve during my one-month robotics sprint. Writing it out in one continuous piece is an interesting challenge — it’s forcing me to connect ideas I’ve thought about individually but never fully considered in relation to one another.
In the afternoon, I talked to a friend who’s trying to build rockets — actual rockets, competing with SpaceX and Isar Aerospace. In the evening, I met two other friends, both with robotics backgrounds but now working on AI agents.
The first conversation left me more optimistic about my own ideas than the second. The rocket friend made the impossible feel exciting. The robotics guys were encouraging but kept emphasising how hard robotics is. They’re not wrong — but the way they said it made the whole thing feel… heavy.
I’ve noticed this before: some conversations give you energy, others consume it — not maliciously, but through realism that turns into inertia. Are energy-giving conversations just sugar highs? Maybe. Doubt might be more accurate, but it’s rarely more useful when the only way to find out is to keep going.
London
Thursday, 15th of May
I’m trying to understand whether I want to move to Paris or London after the next two months in SF. A friend is celebrating her birthday, so it was a good occasion to fly here.
I met two VCs I’d spoken with before. One is an older friend working at a Series A & later-stage fund; the other is an early-stage VC I’d met once and wanted to reconnect with before I’m in a fundraising position.
Talk: Connecting Robotics and Foundation Models by Google Robotics. It discusses several recent papers.
They’re taking a very different approach from Physical Intelligence and rely more on explicit task planning.
Once again, diversity of data trumps quantity: a model trained on 75% of the tasks performs about as well as one trained on 50% of the data.
sdf
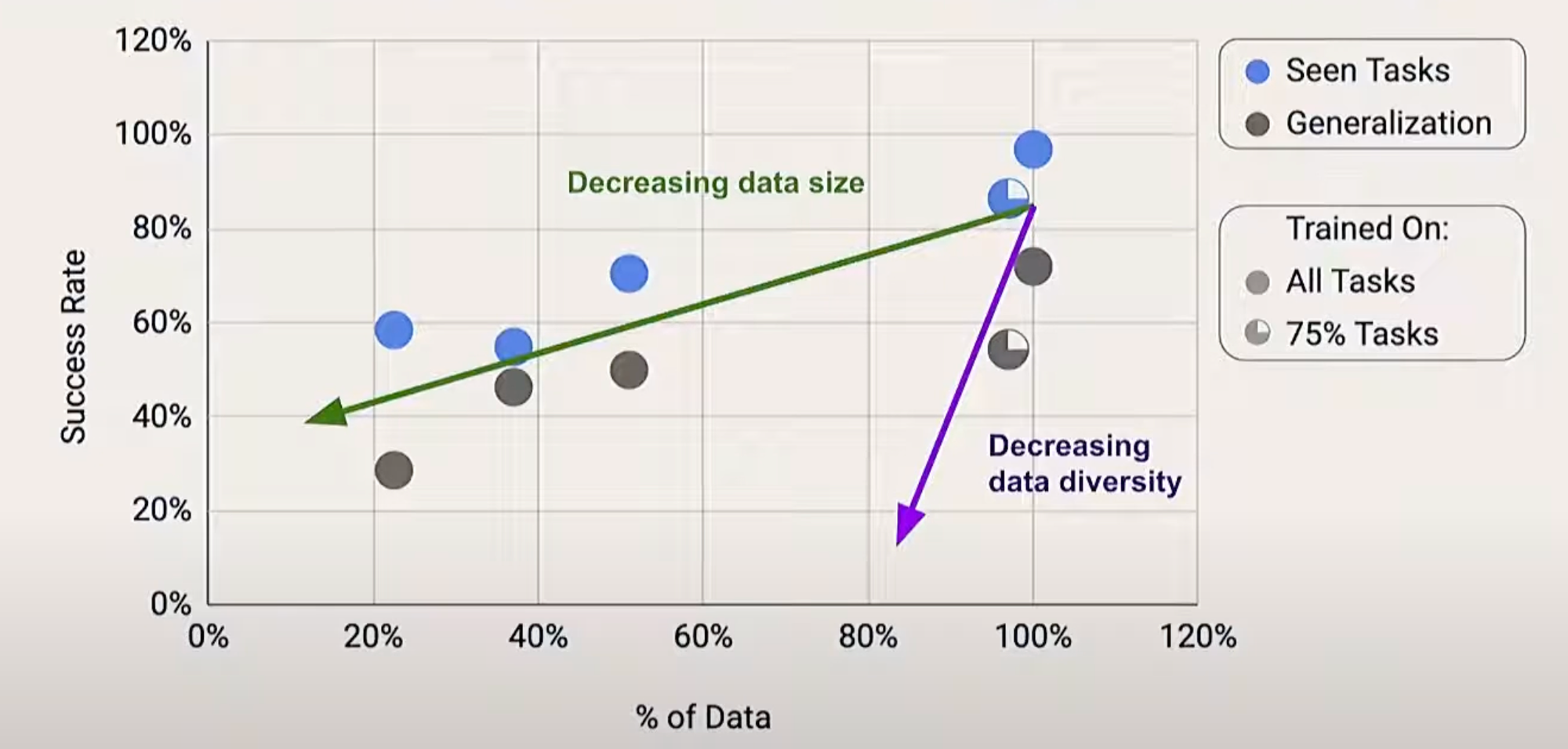
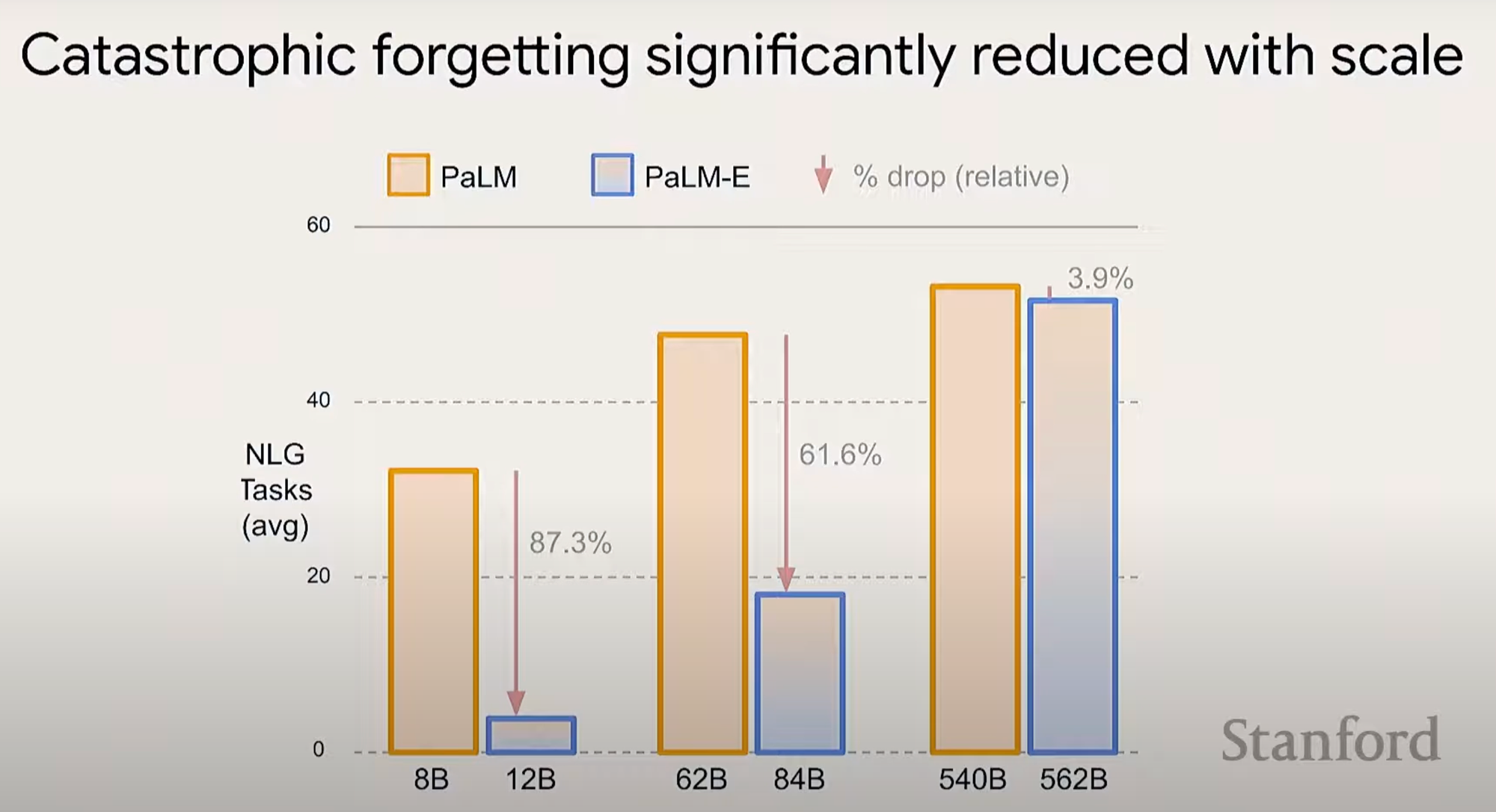
Larger models are less likely to exhibit catastrophic forgetting when trained on new data.
Talk: Bernt Børnich from 1x Robotics. He emphasises the importance of data, and connecting this with the previous talk, I wonder whether household robotics with humanoids is so interesting to companies because of the data diversity you could collect there.
Symposium Münster
Tuesday & Wednesday, 13th & 14th of May
I was invited to speak for 45 minutes about recent developments in AI and to join a panel. I enjoyed giving a talk with a call to action to start building. You can find the slides online if you’re interested. I had agreed to speak a long time ago — after seeing how much time it took, I’m not sure I’d do it again.
Monday, 12th of May – Day off
Zurich Robotics Hackathon
Friday to Sunday, 9–11th of May
We were a team of four and attached an SO-100 arm to a Unitree Go2 quadruped, with the goal of having it retrieve objects in the room. We trained an ACT policy on picking up a tin can and a roll of tape (~60 episodes per item). This worked with ~60% accuracy.
We used OpenAI to perceive the environment, interact with the user via voice, and trigger the ACT policy when it detected proximity.
Demo here: https://x.com/gdb/status/1921963245071475107. Greg Brockman retweeted it — very cool.
I had to dig much deeper into the LeRobot code and learnt a lot. I want to spend much more time working with the lower-level code, not just the higher-level API.
It was very fun playing with the Unitree Go2 and their humanoid. I also met a lot of interesting people again. Amusingly, while every project worked at some point, all six team demos failed during the final presentations.
Flying to Zurich on Friday, I watched talks from Sequoia’s “AI Ascent” playlist. I particularly liked Jim Fan’s talk on the future of robotics and Bret’s talk on agents.
Moving from Phospho to LeRobot code & market research
Thursday, 8th of May
Today, I wanted to understand the robotics market (size, growth, geo split) and how it compares to the AI market. I created a table of market sizes, CAGRs, and geographical distributions. I’m still not sure how much market-size estimates should influence my thinking.
Previously, I used Phospho as the interface for the SO-100. It saves a lot of time but hides a lot of complexity. It was great to get started, but I now want to write my own code. For this I need to use the LeRobot code from Hugging Face. It’ll take time to dig into the codebase, but it’ll be useful for truly understanding robot interfaces.
I recorded a dataset with (1) a context camera and (2) red tape on the SO-100’s claw to help the ML model. I used Phospho to train an ACT model, but it crashed. These feedback loops are too slow — I want to train multiple models on my own GPUs and have more control.
One shortcoming of the SO-100 is its limited reach (~40 cm) and lift (~300 g). I’ve been eyeing what hardware the next level might be. Reading the LeRobot code, I found the Koch v1.1 (built on Alexander Koch’s original design). It costs ~€668. I thought it might be an upgrade to the SO-100, but the reach looks similar; for lift I might as well upgrade the SO-100’s servo. The next true upgrade is probably the Agilex PiPER (€2,699).
Wednesday, 7th of May – Day off
Pi0 paper, ACT model
Tuesday, 6th of May
I found this project where someone built two robots that play chess against each other. They use digital markers + an ACT model to teach where to lift pieces. This is the second SO-100 chess project I’ve seen, besides this one.
The ACT model I trained yesterday crashed; I restarted a new run. Somehow it still isn’t working. Next: try context camera + training directly using LeRobot. Phospho is cool but limited.
I read the π0 paper from Physical Intelligence. Key takeaways:
For robotic foundation models, you want to pre-train on diverse, messy data — including mistakes and recoveries. This teaches robustness. Then fine-tune on fast, clean execution data.
LLMs are enabled by internet-scale data. Robotics has nothing comparable. Data collection is a moat. Physical Intelligence used 10,000 hours of data from 7 robot configs + 68 tasks — 3.5 years of data (8h/day).
Their results:
Pretraining on diverse data improves performance in all but one test.
Over-finetuning on a task can degrade performance.
The model shows zero success at genuinely unseen tasks (no emergent ability).
Breaking tasks into smaller subtasks improves performance.
Idea: Users of the SO-100 upload datasets publicly to Hugging Face. You could recreate a π0-style pretraining setup by training a VLM on that combined data, and see if it accelerates learning.
Aloha paper + new chess recording
Monday, 5th of May
I read the ALOHA paper. One part of its contribution is developing a low-cost arm for $20,000 — which felt extremely expensive. The SO-100 is €200 for leader + follower; I assumed the “next tier” would be €2,000–€3,000. But the cheapest UR arm is €23,500, and Franka is similar. How is hardware so expensive when Unitree’s humanoid is $16k? Many robotics startups seem to be building their own arms to keep cost down (e.g., Tau Robotics, AQL Robotics). The cheapest arm I found was the Agilex PiPER (€2,500).
By the end of the month I want to write a “Robotics 101” guide summarising everything I’ve learnt. I started outlining it, researched robotic-arm companies, and compiled founding dates + funding amounts for major robotics startups.
The model I trained yesterday still doesn’t work. I collected another dataset of 50 e2→e4 pawn moves in the new office to test whether lighting changes were the issue. The new model also doesn’t work: it goes through the motions but doesn’t open the claw or touch pieces. After asking on the Phospho Discord, someone suggested:
(a) I might be moving too fast in the training demonstrations, and
(b) there might be an issue with the contrast between the gripper and the chess pieces.
This makes me think I’ve overestimated the capability of Gr00t and robotic FMs in general. Next step: train an ACT policy.
Ordered a webcam, grip tape, and a mount for the camera.
Goals for this week:
Learn how to train ACT, Gr00t, and Pi0 models on the SO-100 arm.
Read the three papers, understand differences, summarise in the 101 post.
Brainstorm project ideas for the Zurich robotics hackathon.
Questions from today:
Will I eventually need to build my own robot to iterate cheaply and get stronger hardware than the SO-100?
How important is the number of cameras for good training results? (ALOHA uses four.)
First training with the SO-100
Sunday, 4th of May
I trained a simple Gr00t model to move a pawn from e2 to e4 using 50 samples. It’s not working yet: https://x.com/DominiqueCAPaul/status/1919029034895167952.
I realised I probably wasn’t training long enough. Started with 10 epochs, tried 25, still not enough. Kicked off a 50-epoch run overnight.
Friday:
Found ACT tuning tips: https://docs.google.com/document/d/1FVIZfoALXg_ZkYKaYVh-qOlaXveq5CtvJHXkY25eYhs/edit?tab=t.0#heading=h.2xiz3mdijyv4
Realised ACT and diffusion policies may not be training long enough.
Thursday:
Evaluated models from yesterday — they’re bad.
Looked into diffusion-policy papers and started a training run. DataLoader very slow.
Created issues on LeRobot (also for SmolVLA).
Thought about working at Physical Intelligence.
Caught up with Elvis, talked to a friend, went to a disappointing robotics mixer. Lesson: just do 1-on-1 calls.
Thought about spending more time on GVL; not sure how it helps with the chess robot.
Wondered what loss functions ACT, SmolVLA, and diffusion policies use — can I compare loss vs. samples seen?
Replicating the Generative Value Learning Paper
Wednesday, 10th of July
I collected the last episodes this morning and then went through the data to ensure there are no errors in what the model will learn from. I merged the datasets using Phospho and am now waiting for the upload to Hugging Face to finish.
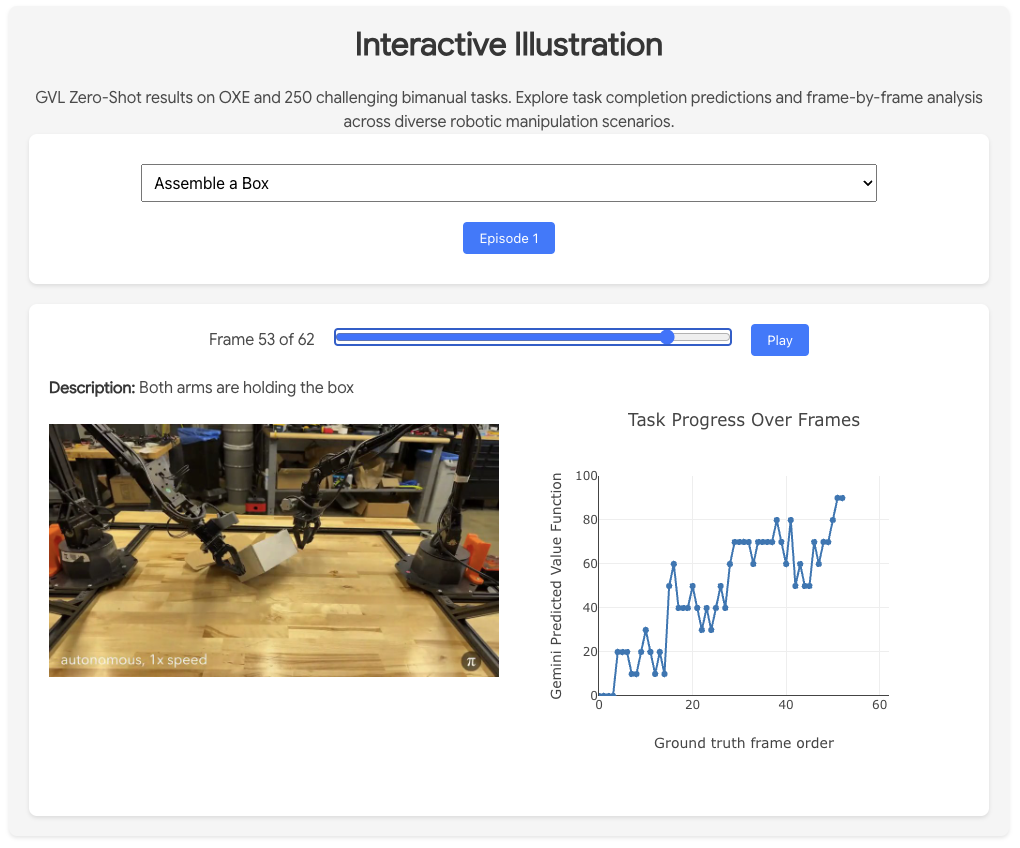
In the meantime, I read the paper Vision Language Models are In-Context Value Learners, written by the Dyna founder during his PhD and foundational to the company. The paper proposes Generative Value Learning (GVL), which uses a frozen VLM to assign progress scores (0–1) to video frames of a robot performing a task.
The key idea: naive prompting yields uninformative, monotonic “always increasing” scores because of temporal bias. GVL breaks this by shuffling the frames and framing the task as a temporal ordering problem, forcing the VLM to reason about task semantics.
These frame-wise scores can then be used for:
success detection (e.g., filtering failed trajectories),
dataset-quality estimation,
advantage-weighted imitation learning — letting robots learn from their own trajectories, without any external reward labels or supervision.
This is what it looks like in the Dyna research blog post:
This is from an experiment I did comparing the Gemini models and GPT:
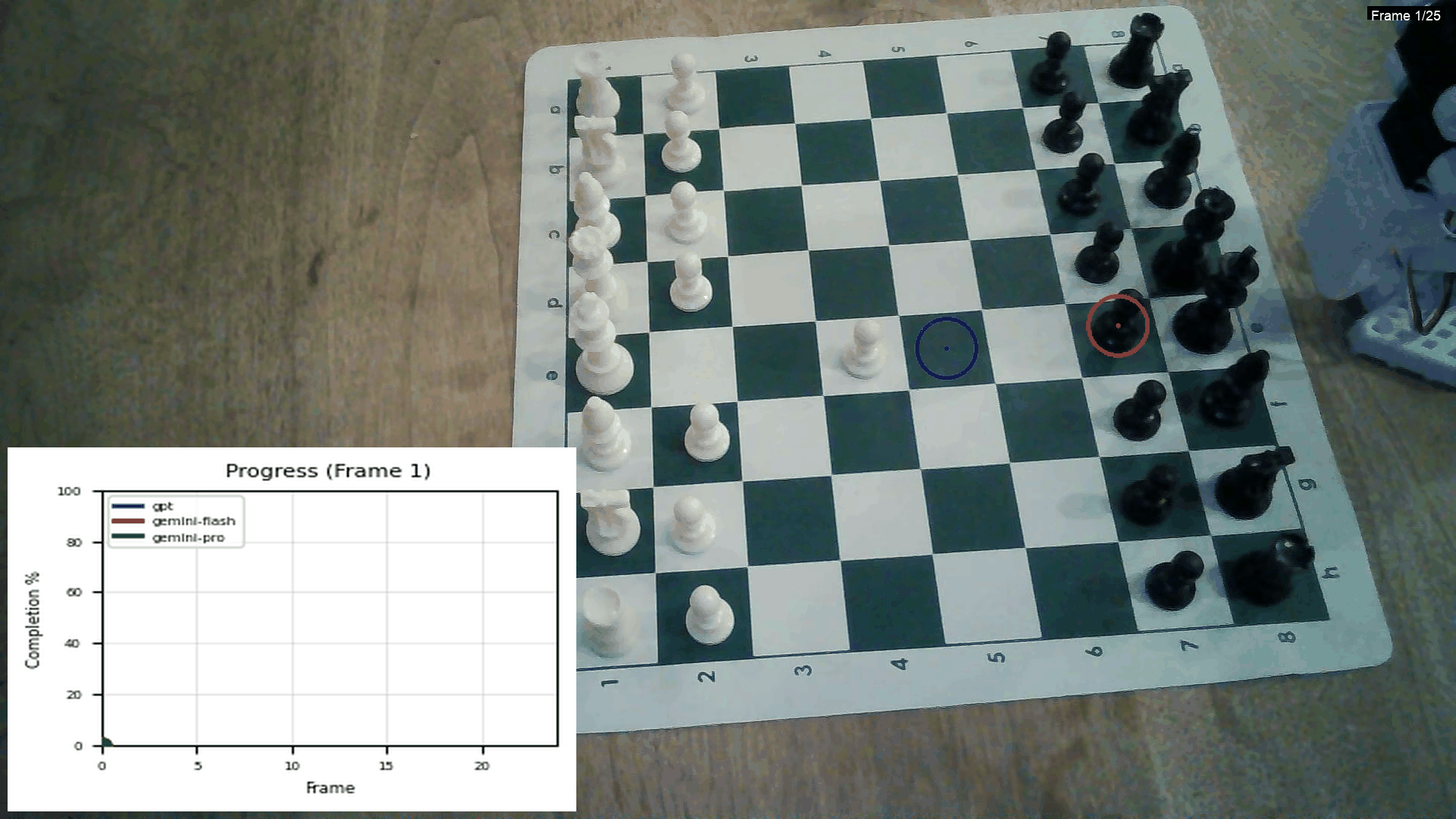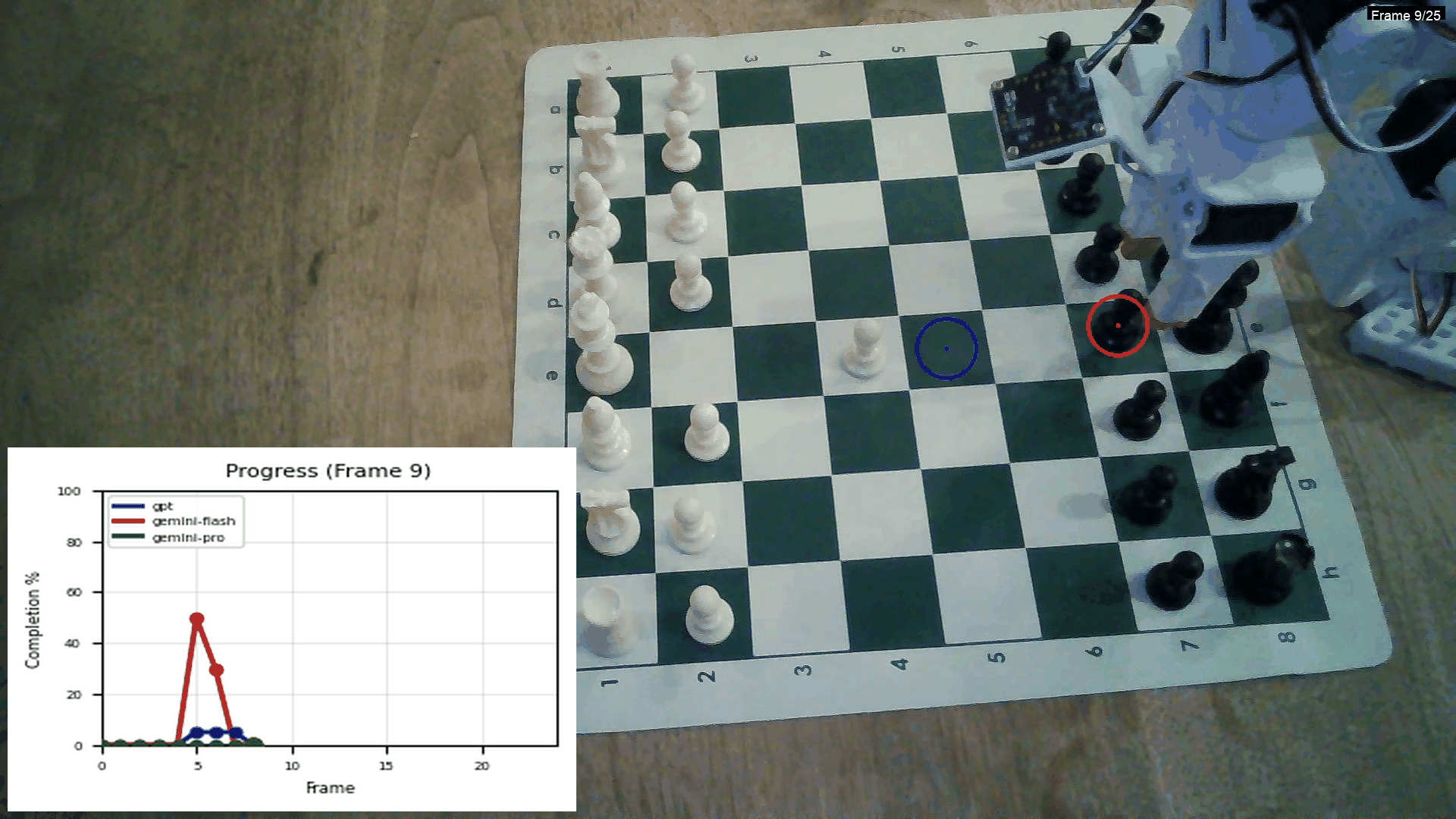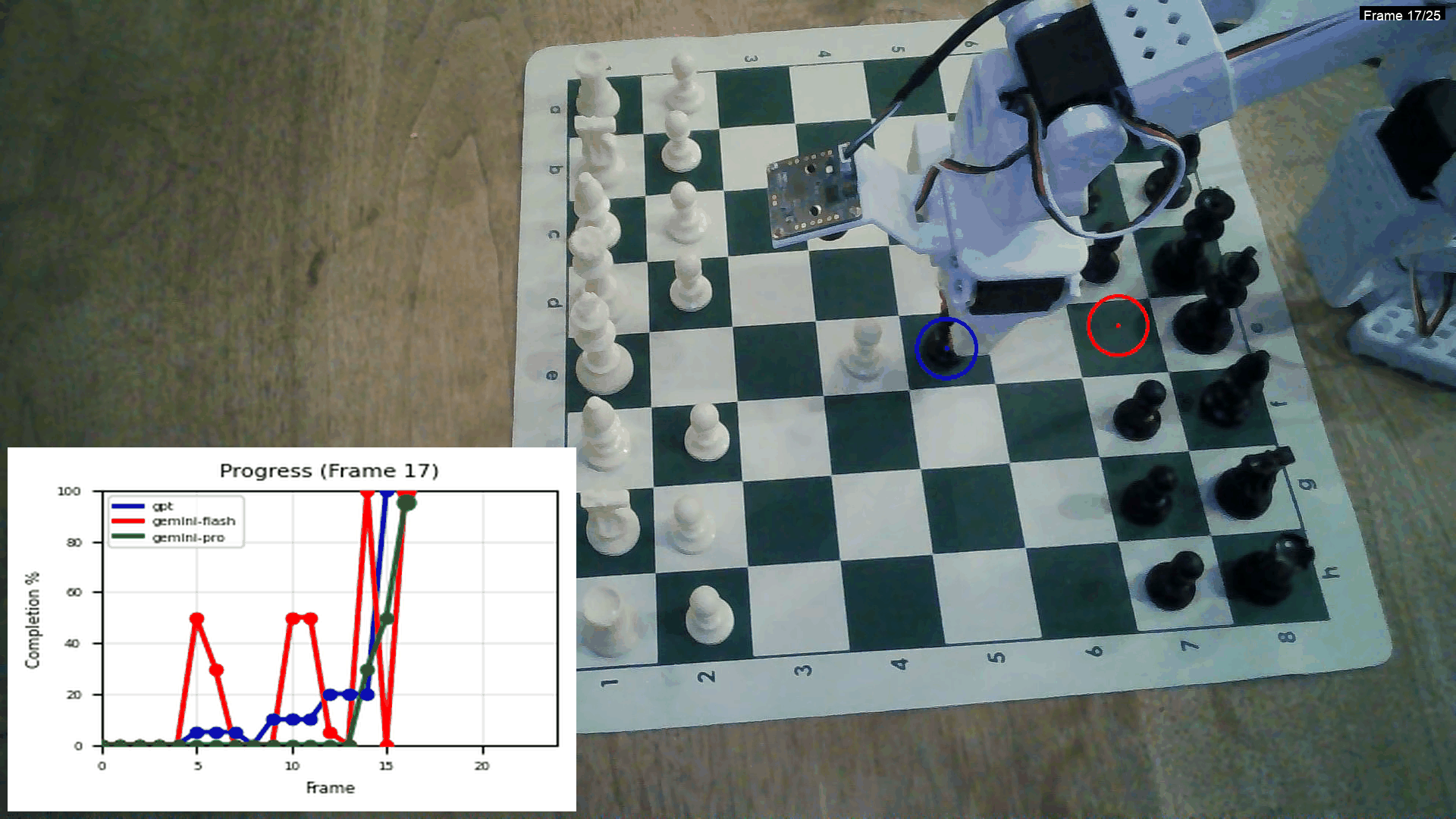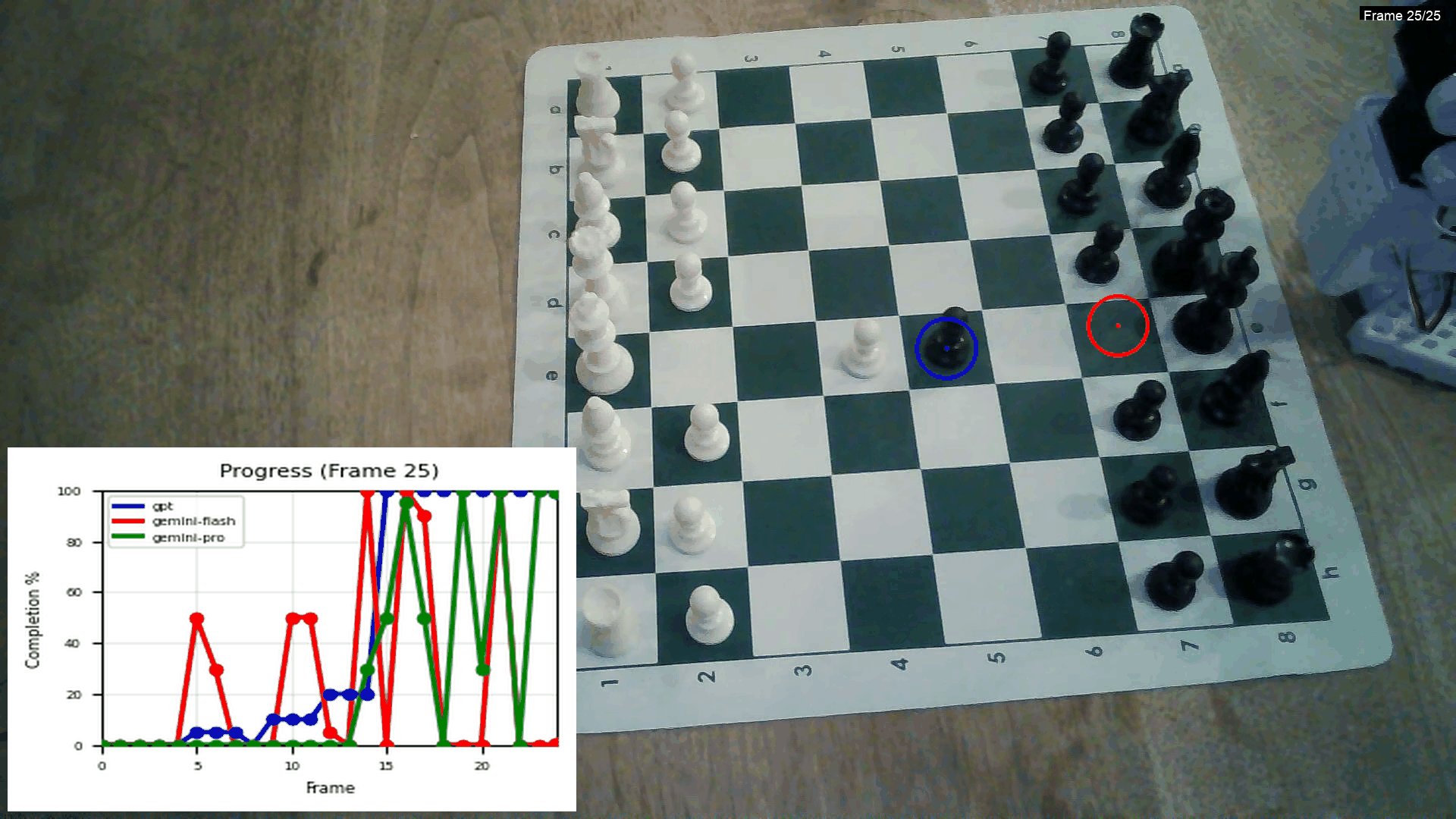
Using GPT for this is really expensive though! Creating 5–10 of these videos costs $2. One thing I haven’t implemented yet is an in-context example with frames of the task — this might make the lines significantly smoother.
Why am I doing this?
While I hope that the model trained on 1,500 samples will be significantly better than the one trained on 500, I’m certain it won’t work with >90% success. I’ve been thinking about how I could get there (beyond just collecting more data). Applying this method to data collected autonomously by the robot could be an interesting path.
Also, I enjoyed listening to this podcast with Karol Hausman, CEO of Physical Intelligence (and a staff researcher). Highly recommend it.
Collecting 1,500 episodes
Monday & Tuesday, 8th/9th of July
I spent the days collecting data. The changes to the recording script hugely improved the time required. What used to take 1 hour is now roughly 20 minutes of data collection plus 40 minutes of processing where I can do other work — like continuing to read the General Robots Substack, which I also highly recommend.
I also had some time to reflect and summarise a few learnings:
Don’t save on webcams.
I bought a €60 webcam instead of the Logitech C992 used in the ALOHA paper. The cheap camera is extremely sensitive to light: in indirect daylight, white pieces and parts of the board are overexposed. This likely hurts the model’s ability to learn.
Regularly inspect your own data and ask whether it’s optimal for learning.
I noticed the camera on the robot arm isn’t focused (you can adjust this manually). Maybe this adds some robustness, but with a fixed data budget, more blur just means lower quality.
If you build a robot, try to keep lighting as constant as possible.
Seeing the lengths Dyna went to for constant lighting made sense after reviewing my own data. Lighting varies a lot depending on the time of day.
I underestimated the number of samples required to get a decent model (I’m not sure 1,500 episodes will be enough), and I originally thought robustness across environments would be nice — closer to a real-life setting.
True… but also very painful. I’d now be happy to have a model that reliably works in one environment.
Goal Setting for the Week & Augmenting Script for Faster Data Collection
Sunday, 6th of July
My big hypothesis from last week is that I most likely need way more data. I want to confirm or disprove this as quickly as possible. I planned the week and set three main goals:
Collect 1,100 episodes and retrain the ACT & SmolVLA models
Annotate 300 images for the piece-detection model and retrain it
Connect the chessboard-reading code with the model that executes the move
I also want to use the early mornings — during the data-collection days — to get some reading done while I’m still fresh.
The biggest bottleneck last week was post-processing: a 15s episode took 30–40s to encode immediately after recording. This slowed down the loop a lot.
I updated the LeRobot code so that image-to-video processing now happens in batch afterwards. This should halve the time per episode, if not more.
I also read this Substack on scaling laws for VLAs.
Meeting people for coffee and 4th of July
Friday, 4th of July
I met friends visiting SF and a friend from the robotics hackathon in Paris who’s also starting a company. I also took some time off to celebrate the 4th of July.
Ok, it was time for a shitty day again
Thursday, 3rd of July
Today I kicked off training for an ACT and a SmolVLA model. In the early evening, I tested the first checkpoints and was disappointed. The 20k SmolVLA checkpoint doesn’t work at all, and the 80k ACT checkpoint (the furthest available at the time) isn’t much better.
SmolVLA model trained for 20k steps at a 8 sample batch size:
ACT model trained for 80k steps at a batch size of 8:
I need to wait for the final results, but I’m not quite sure what’s best to do if the final models aren’t better tomorrow. I’m going to think out loud:
First, I should do a systematic evaluation of the checkpoints to understand:
Which of the two models is working better, and is it by a clear margin?
Does longer training (later checkpoints) lead to better results? → If yes, then train a model beyond 100k steps.
The 100 samples where I only move the rooks could be confusing to the model. Does a model trained without this data do better?
I could collect another 500 episodes, train on the joint dataset, and see if this improves the model.
I could do a literature review on how others have trained imitation-learning models and see if there are any tricks to get this done.
Ok, I just revisited this video I’d seen 1–2 months ago of someone else who built a chess robot. I noticed the description saying it’s trained on 1,500 episodes! I currently have 500 — or 400 if you only count episodes from chess games — so maybe I just need to collect more data.
The robots in the video have a better setup:
The robots are in a fixed position relative to the chessboard, and
Their camera is pointing at the pieces from below, such that the pieces are in view from the beginning.
Maybe the solution really is just collecting more data.